Guest post by Olivier Dupuis
Discursus 0.0.3 is out and we’re excited about the new machine learning (ML) layer we’ve added. It opens up a world of possibilities and we want to share how we tackled that challenge and what it means for the discursus project.
This release leverages Dagster, dbt and Novacene AI to enrich data in the production of data assets. This allows for a very versatile, stable and efficient process to automate the production of data assets.
Architecture
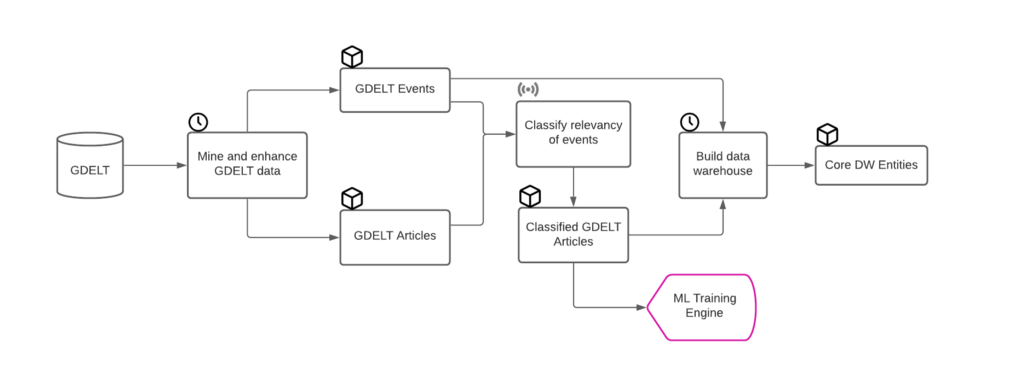
To set the context, here’s a diagram of the data asset production flow for discursus.
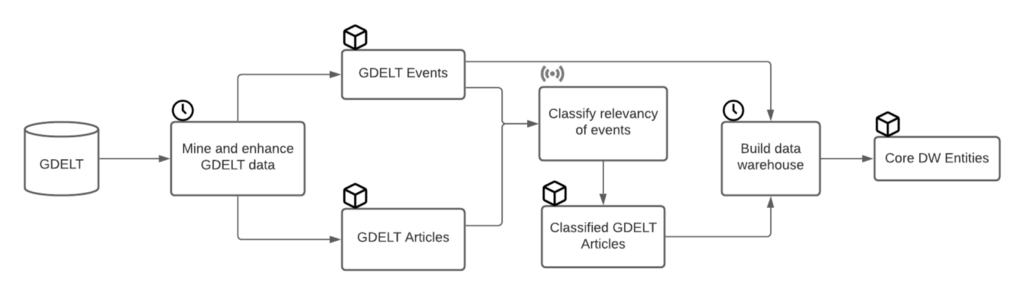
Couple of points to note:
- GDELT remains our main source of data for the moment. We have plans to broaden that list, but for now we are focused on extracting the most value out of that single source.
- We have 2 types of triggers (which are essentially Dagster APIs) for each job: schedules that run at regular time intervals + sensors that run whenever an asset is materialised.
- The ML component (classification of relevancy of events) is only a single step in the data asset production flow for now. That’s where we’ve added the ML layer in version 0.0.3 and that’s what we’re focusing on here.
This flow is supported by the following architecture.
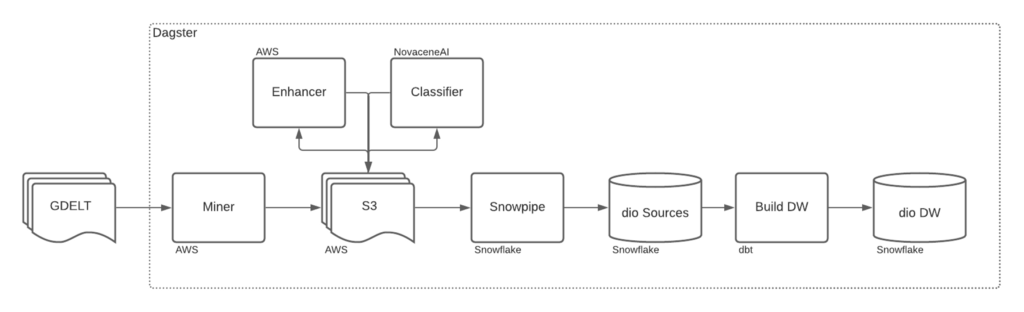
Its components are:
- A miner that sources events from the GDELT project and saves output to AWS S3.
- An enhancement process that scrapes the article’s metadata and saves output to AWS S3.
- An ML enrichment process that classifies article’s relevancy using a trained ML model hosted on Novacene.ai and saves results to AWS S3.
- A suite of Snowpipe functions that loads S3 data to Snowflake.
- A dbt project that creates a data warehouse which exposes protest event entities.
- A Dagster app that orchestrates all data transformation jobs and the creation of assets.
Let’s explore further the Machine Learning as a Service (MLaaS) layer we’re introducing in this project.
MLaaS — Training, hosting and using ML models
Full disclosure, Novacene AI is a supporter and a friend of the discursus project, and since theirs is a high-quality service and the team is knowledgeable and always ready to help, it was an obvious choice for me to use this MLaaS platform in the discursus project. Of course, just like S3, dbt, Dagster and Snowflake could all be replaced with equivalent tools, other suitable MLaaS would likely work here too.
That said, we’ve seen how Novacene fits into our data asset production flow, as well as in our architecture. To frame the process of how we work with this service, here’s a diagram of how discursus and Novacene AI interact together.
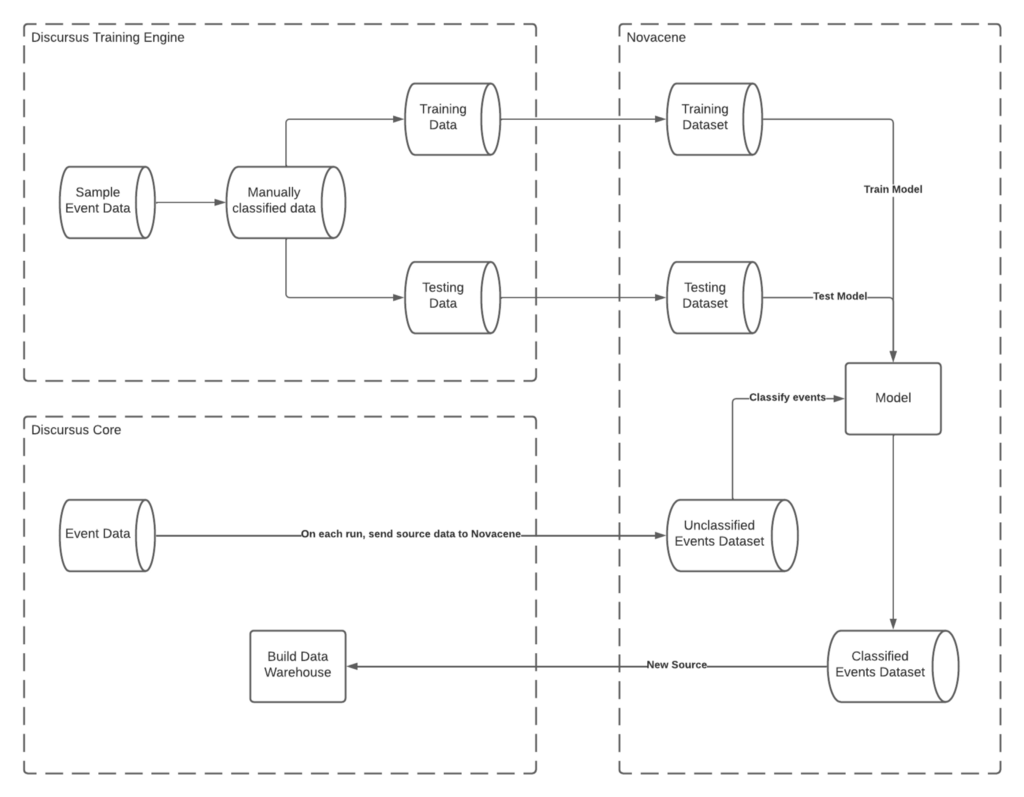
Let’s briefly go over each of those steps:
- As we’ll see in our ML Training Engine section, we have a process to manually classify the relevancy of a sample of our data. We then use that source to create enhanced training and testing datasets to further train our ML models.
- We initially trained our classifier using a text classification algorithm. As we continue manually classifying streaming events through our ML Training Engine, we periodically retrain that model to continuously optimise it.
- As we mine new data from GDELT and scrape its associated metadata (page title, description and keywords), we have a sensor that sends those new assets to Novacene for ML enrichment.
- We then have a scheduled job that lookup the Novacene job statuses. For each completed job, we download the result, save it to S3 and use a Snowpipe function to stage that data in Snowflake.
- This becomes a new source in our dbt data warehouse job, which we use to filter out irrelevant events and only keep high-quality protest events in our final dataset.
Novacene is ideal for the discursus project as we can easily train and test models with existing / custom algorithms, host our ML models, send data for enrichment and then retrieve the results. We do all this through their very flexible API.
As a side note, if you’re considering working with Novacene and need a Dagster resource to interact with it, have a look at the one we’ve put together for discursus.
ML Training Engine
The ML Training Engine is our internal process to manually classify streaming events to continuously improve our ML models. As we use supervised algorithms, we needed a process to introduce a human in the middle.
Essentially, as we mine and enrich new data, we send a sample to a Airtable base which provides a very convenient interface to work with. That sample includes the event’s article metadata, as well as our Model’s classification prediction. We can then tag those classifications as accurate or inaccurate.
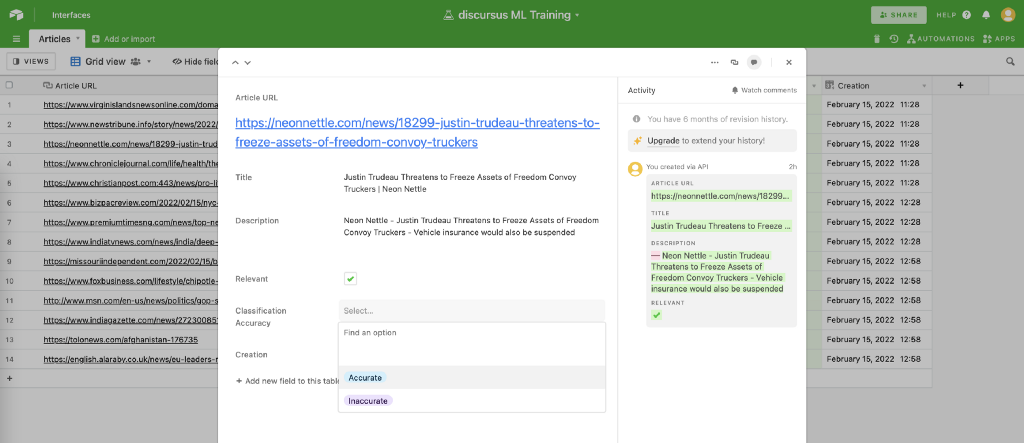
With time, we can use a larger dataset with better manually classified examples to retrain our ML model.
What it means for discursus
As a reminder, the discursus project is an open source data platform that mines, shapes and exposes the digital artifacts of protests, their discourses and the actors that influence social reforms. As a data platform, that means we aim to expose the entities (events, actors and narratives) that are encapsulated in protest movements, as well as their relationships.
We want to create a data platform that will allow analysts to explore, visualise and convey the story arcs of protest movements. That means an analyst should be able to explore the dynamics between entities, the timeline of those dynamics, as well as the narratives that trigger the movement, sustain it and eventually leads to their end.
We’re still a long way to being able to tell data-rich stories about protest movements. But we hope machine learning will help us improve the quality of our data which defines those entities, their relationships and how they morph through time.
Guest post by Olivier Dupuis. Olivier is the founder and lead consultant at a prominent analytics company, where they help data product owners deliver high quality data to their users. They also host and lead the development of the open-source Data Product Framework, which provides the architecture and suite of libraries to quickly source, transform and deliver data assets.
