How to deploy an ML model and use it in your data pipeline as a web service.
Operationalizing a model refers to the process of deploying a machine learning model (ML) to be used with a client application such as a web app. Automating the ongoing ingestion of data and running machine learning (ML) models is a scenario perfectly suited for modern data stacks. A lot of workflows are currently moving to the cloud and it’s no surprise that ML is one of them. If you are looking to deploy ML models in the cloud, here’s an article on how to use Microsoft Azure to drive the data orchestration and continuous integration of an ML pipeline. There are many ways and tools that can be used to achieve this. Here we describe one approach.
Microsoft Azure Machine Learning Studio
Web services in Azure facilitate managing your website without getting involved in the details of implementations such as storage, environment, and compute nodes. Azure ML is a web-based IDE (integrated development environment) for developing a variety of ML experiments, running them in cloud and generating responsive app services that can easily connect your web service with a ML model.
If you wanted to deploy your ML model as a web service in the Azure cloud, you will need to:
- Setup Azure Environment
- Register the ML model
- Prepare an inference configuration and the entry script
- Define a deployment configuration and deploy the model
Setup an Azure Environment
We’ll begin by setting up the environment and getting it ready to train an experiment. In order to pass the model to Azure you need to connect to the Azure workspace, so that your local computer can communicate with remote resources. Every workspace is comprised of an experiment that tracks all the training scripts and an environment that encompasses all the required packages for the training scripts to run. The environment is also a necessary part of the final deployment in Azure.
Register the trained model
We need two components for deploying an ML model; trained models that need to be accessed remotely through a deployment and an entry script that loads the packages and the model and responds to a post request. The entry script may also include the preprocessing of data before sending it to the loaded ML model. The entry script makes deployment scalable since a change of model will not require a change to the entry script. Both the model, which is saved on cloud, and the entry script will be transferred to a remote virtual machine for an implementation in a webserver.
Prepare an inference configuration and the entry script
The inference configuration controls the way in which the model will be used to make predictions. It points to an entry script and the path to all the registered models in the cloud for deployment. The entry script is used to return predictions from a registered model. This script has two mandatory sections; an “init” function and a “run” function. The init function connects the entry script to the registered model. The run function executes the prediction function from the model saved during the training.
Define a deployment configuration and deploy the model
This last step describes how to deploy the model and create a web service that can be used for scoring new data. A client can make a web request to the created webserver and Azure will process the input data according to the model and send back the results as a post-request. The easiest way to do this is to wrap the scoring script in a container and deploy it to the Azure ML service. Below you can see an example of such a call to deploy the Model class:

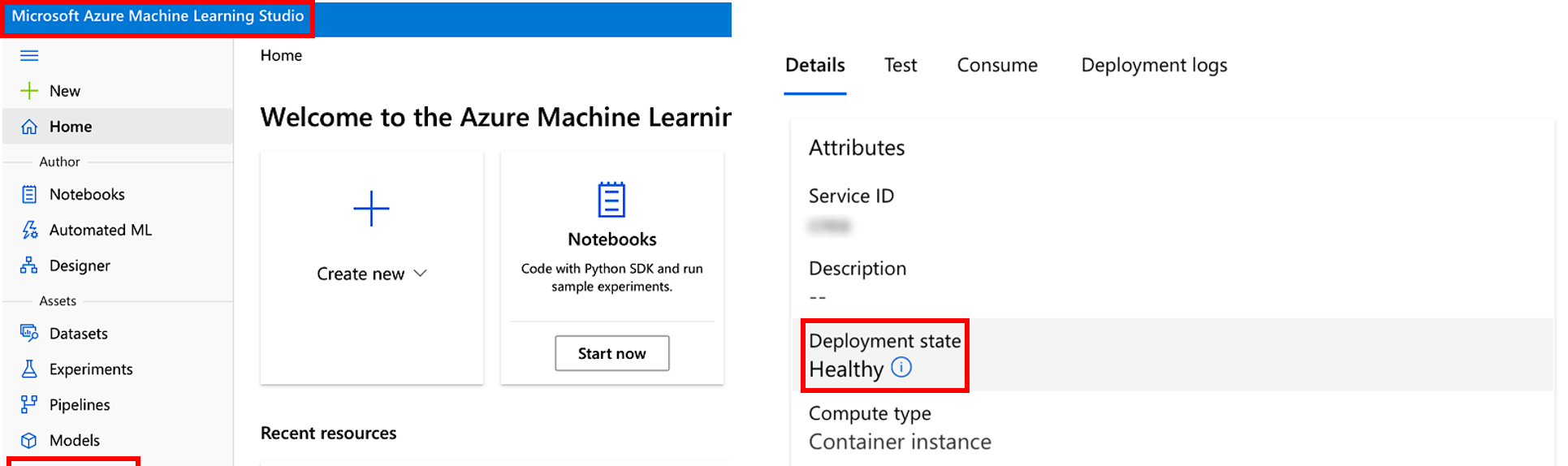
During model deployment, you may see the service state change while it fully deploys. As you can see in the table, if the service is healthy, the endpoint is available.
Summary
The four major components of any ML deployment in Azure have been discussed in this article. Azure machine learning environment provides an easy approach to implement heavy machine learning algorithms as web applications. A client can easily access the result of the machine learning process by a simple web request to the server.
