Data & Analytics Modernization
Transform data into actionable insights with advanced AI-driven automation, streamlining decisions and accelerating your business.
Trusted by Leading Organizations






Transform insights into action with ease. Our Intelligent Automation solutions use AI to streamline workflows, optimize decisions, and keep your business ahead.
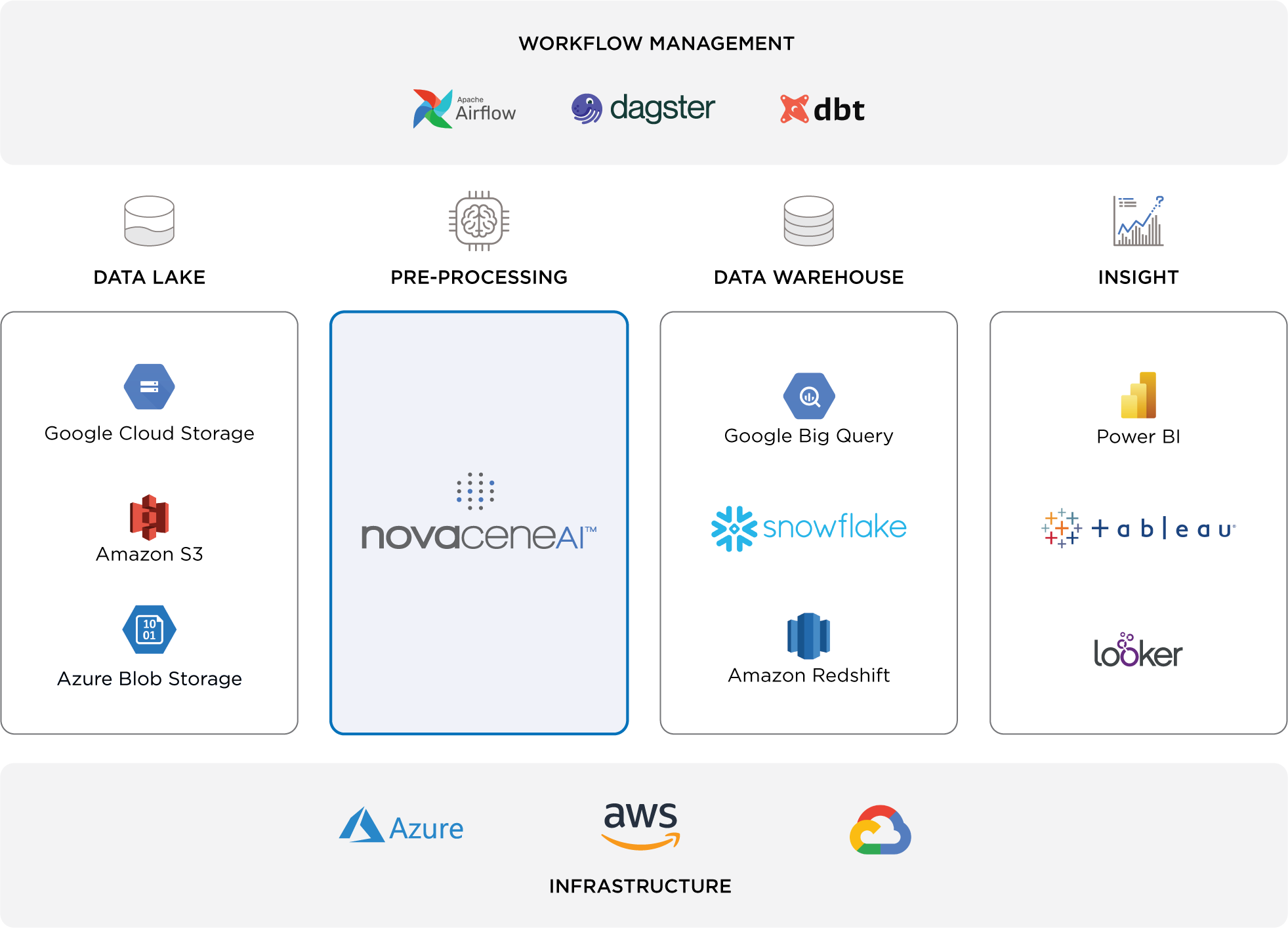
Built for the Modern Data Stack
A cloud-native data pre-processing tool for unstructured data
The platform is designed to help data professionals leverage AI and Machine Learning in their data processing workflows. The platform enables data teams to go beyond simple transformations, and use intelligent algorithms to structure data.
Use Cases
Security Operations Automation
Systematic decision making. Use AI and ML to learn from past expert decisions and suggest the way forward. Assist analysts with automated smart data enrichments that suggest recommended actions, bringing consistency to their workflows.

Law Enforcement Leverages AI to Access Encrypted Evidence
NovaceneAI helps law enforcement agencies strengthen public safety with AI solutions that enable lawful access to encrypted data.

Data Quality Automation
Automate the detection and remediation of inaccuracies in your data. Free up busy quality control staff to focus on higher value tasks.

What Our Clients Say
Leaders Across Industries Share How NovaceneAI Delivers Real Impact.
From cybersecurity and mining to market research and law enforcement, organizations trust NovaceneAI to solve complex challenges with AI. Here’s what our clients and partners have to say about working with us — in their own words.
“Attackers are constantly evolving and analysts are playing catch up. NovaceneAI’s predictive solution makes it possible for us to stay ahead and deliver consistent results.”
Vice-president, Managed Security Services, KPMG
“NovaceneAI is helping us identify which variables truly affect lithium production. What once took our engineers hours of manual work can now be streamlined and scaled with AI.”
Head of Lithium Exploration and Project Development, Lithium Americas
“We’ve long believed that understanding a person improves the ability to predict their passwords. With NovaceneAI, we can finally test that theory with real data — and the results are exciting.”
Professor of Cryptography, University of Ottawa
Governance Overview
See how the NovaceneAI Platform safeguards the privacy and security of customer data.

